 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRGuard: Guarding Agent Actions with Runtime Authority Control
May 27, 2026Tool-using language agents turn model decisions into external side effects: they read files, run scripts, call APIs, send messages, and invoke Model Context Protocol tools. This makes agent attacks different from jailbreaks. The harmful step is often not an obviously forbidden output, but an ordinary executable action that becomes unsafe because attacker-controlled context steers authorized access against the user's interest. We identify this failure mode as authority confusion: untrusted resources may inform reasoning, but they must not authorize side effects. We present AIRGuard, a runtime guard that operationalizes least privilege as action-time authorization. AIRGuard normalizes heterogeneous tool calls, derives task authority into step-level authority, tracks source and target trust, simulates sensitive side effects, audits cross-step risk, and enforces decisions before actions execute. On AgentTrap, AIRGuard reduces Sonnet 4.6 attack success from 36.3% without defense to 5.5%. On DTAP-150, AIRGuard preserves 76.0% benign utility with Haiku 4.5, compared with 52.0% for ARGUS and 42.0% for MELON. An ablation further shows that prompt-only policy helps only modestly, whereas a dedicated runtime authority-control layer gives the agent system direct control over tool-mediated side effects. Code and data are available at https://github.com/Sophie508/AIRGuard.
AgentTrap: Measuring Runtime Trust Failures in Third-Party Agent Skills
May 13, 2026Third-party skills are becoming the package ecosystem for LLM agents. They package natural-language instructions, helper scripts, templates, documents, and service configuration into reusable workflows. This makes skills useful, but it also introduces a new security problem: a malicious skill does not need to ask the model to perform an obviously harmful action. Instead, it can disguise the harmful behavior as part of a routine workflow, relying on the agent to execute that workflow with high-value permissions and limited human supervision. We introduce AgentTrap, a dynamic benchmark for evaluating whether LLM agents can use third-party skills while resisting malicious runtime behavior. AgentTrap contains 141 tasks: 91 malicious tasks and 50 benign utility tasks, covering 16 security-impact dimensions grounded in agent-skill supply-chain threats. In each task, the agent receives an ordinary user request, runs with installed skills that may contain malicious workflow elements, and is executed in a sandboxed environment. AgentTrap then judges complete trajectories for attack success, blocked or refused behavior, attack-not-triggered cases, and no-attack-evidence outcomes. Our central finding is that the most informative failures are not simple jailbreaks. Models often complete the visible user task while treating unsafe side effects introduced by the skill as part of the normal workflow. This motivates runtime evaluation of the concrete model--framework--workspace environment in which users actually delegate work. Code and data are available at https://github.com/zhmzm/AgentTrap and https://huggingface.co/datasets/zhmzm/AgentTrap.
Too Correct to Learn: Reinforcement Learning on Saturated Reasoning Data
Apr 20, 2026Reinforcement Learning (RL) enhances LLM reasoning, yet a paradox emerges as models scale: strong base models saturate standard benchmarks (e.g., MATH), yielding correct but homogeneous solutions. In such environments, the lack of failure cases causes the advantage signal in group-relative algorithms (e.g., GRPO) to vanish, driving policies into mode collapse. To address this, we propose Constrained Uniform Top-K Sampling (CUTS), a parameter-free decoding strategy enforcing structure-preserving exploration. Unlike standard sampling that follows model biases, CUTS flattens the local optimization landscape by sampling uniformly from constrained high-confidence candidates. We integrate this into Mixed-CUTS, a training framework synergizing exploitative and exploratory rollouts to amplify intra-group advantage variance. Experiments on Qwen3 models demonstrate that our approach prevents policy degeneration and significantly boosts out-of-domain generalization. Notably, Mixed-CUTS improves Pass@1 accuracy on the challenging AIME25 benchmark by up to 15.1% over standard GRPO, validating that maintaining diversity within the semantic manifold is critical for rigorous reasoning.
PolicyLLM: Towards Excellent Comprehension of Public Policy for Large Language Models
Apr 14, 2026Large Language Models (LLMs) are increasingly integrated into real-world decision-making, including in the domain of public policy. Yet, their ability to comprehend and reason about policy-related content remains underexplored. To fill this gap, we present \textbf{\textit{PolicyBench}}, the first large-scale cross-system benchmark (US-China) evaluating policy comprehension, comprising 21K cases across a broad spectrum of policy areas, capturing the diversity and complexity of real-world governance. Following Bloom's taxonomy, the benchmark assesses three core capabilities: (1) \textbf{Memorization}: factual recall of policy knowledge, (2) \textbf{Understanding}: conceptual and contextual reasoning, and (3) \textbf{Application}: problem-solving in real-life policy scenarios. Building on this benchmark, we further propose \textbf{\textit{PolicyMoE}}, a domain-specialized Mixture-of-Experts (MoE) model with expert modules aligned to each cognitive level. The proposed models demonstrate stronger performance on application-oriented policy tasks than on memorization or conceptual understanding, and yields the highest accuracy on structured reasoning tasks. Our results reveal key limitations of current LLMs in policy understanding and suggest paths toward more reliable, policy-focused models.
Position: General Alignment Has Hit a Ceiling; Edge Alignment Must Be Taken Seriously
Feb 23, 2026Large language models are being deployed in complex socio-technical systems, which exposes limits in current alignment practice. We take the position that the dominant paradigm of General Alignment, which compresses diverse human values into a single scalar reward, reaches a structural ceiling in settings with conflicting values, plural stakeholders, and irreducible uncertainty. These failures follow from the mathematics and incentives of scalarization and lead to \textbf{structural} value flattening, \textbf{normative} representation loss, and \textbf{cognitive} uncertainty blindness. We introduce Edge Alignment as a distinct approach in which systems preserve multi dimensional value structure, support plural and democratic representation, and incorporate epistemic mechanisms for interaction and clarification. To make this approach practical, we propose seven interdependent pillars organized into three phases. We identify key challenges in data collection, training objectives, and evaluation, outlining complementary technical and governance directions. Taken together, these measures reframe alignment as a lifecycle problem of dynamic normative governance rather than as a single instance optimization task.
ProbeLLM: Automating Principled Diagnosis of LLM Failures
Feb 13, 2026Understanding how and why large language models (LLMs) fail is becoming a central challenge as models rapidly evolve and static evaluations fall behind. While automated probing has been enabled by dynamic test generation, existing approaches often discover isolated failure cases, lack principled control over exploration, and provide limited insight into the underlying structure of model weaknesses. We propose ProbeLLM, a benchmark-agnostic automated probing framework that elevates weakness discovery from individual failures to structured failure modes. ProbeLLM formulates probing as a hierarchical Monte Carlo Tree Search, explicitly allocating limited probing budgets between global exploration of new failure regions and local refinement of recurring error patterns. By restricting probing to verifiable test cases and leveraging tool-augmented generation and verification, ProbeLLM grounds failure discovery in reliable evidence. Discovered failures are further consolidated into interpretable failure modes via failure-aware embeddings and boundary-aware induction. Across diverse benchmarks and LLMs, ProbeLLM reveals substantially broader, cleaner, and more fine-grained failure landscapes than static benchmarks and prior automated methods, supporting a shift from case-centric evaluation toward principled weakness discovery.
Capability-Oriented Training Induced Alignment Risk
Feb 12, 2026While most AI alignment research focuses on preventing models from generating explicitly harmful content, a more subtle risk is emerging: capability-oriented training induced exploitation. We investigate whether language models, when trained with reinforcement learning (RL) in environments with implicit loopholes, will spontaneously learn to exploit these flaws to maximize their reward, even without any malicious intent in their training. To test this, we design a suite of four diverse "vulnerability games", each presenting a unique, exploitable flaw related to context-conditional compliance, proxy metrics, reward tampering, and self-evaluation. Our experiments show that models consistently learn to exploit these vulnerabilities, discovering opportunistic strategies that significantly increase their reward at the expense of task correctness or safety. More critically, we find that these exploitative strategies are not narrow "tricks" but generalizable skills; they can be transferred to new tasks and even "distilled" from a capable teacher model to other student models through data alone. Our findings reveal that capability-oriented training induced risks pose a fundamental challenge to current alignment approaches, suggesting that future AI safety work must extend beyond content moderation to rigorously auditing and securing the training environments and reward mechanisms themselves. Code is available at https://github.com/YujunZhou/Capability_Oriented_Alignment_Risk.
Save the Good Prefix: Precise Error Penalization via Process-Supervised RL to Enhance LLM Reasoning
Jan 26, 2026Reinforcement learning (RL) has emerged as a powerful framework for improving the reasoning capabilities of large language models (LLMs). However, most existing RL approaches rely on sparse outcome rewards, which fail to credit correct intermediate steps in partially successful solutions. Process reward models (PRMs) offer fine-grained step-level supervision, but their scores are often noisy and difficult to evaluate. As a result, recent PRM benchmarks focus on a more objective capability: detecting the first incorrect step in a reasoning path. However, this evaluation target is misaligned with how PRMs are typically used in RL, where their step-wise scores are treated as raw rewards to maximize. To bridge this gap, we propose Verifiable Prefix Policy Optimization (VPPO), which uses PRMs only to localize the first error during RL. Given an incorrect rollout, VPPO partitions the trajectory into a verified correct prefix and an erroneous suffix based on the first error, rewarding the former while applying targeted penalties only after the detected mistake. This design yields stable, interpretable learning signals and improves credit assignment. Across multiple reasoning benchmarks, VPPO consistently outperforms sparse-reward RL and prior PRM-guided baselines on both Pass@1 and Pass@K.
Stable and Efficient Single-Rollout RL for Multimodal Reasoning
Dec 20, 2025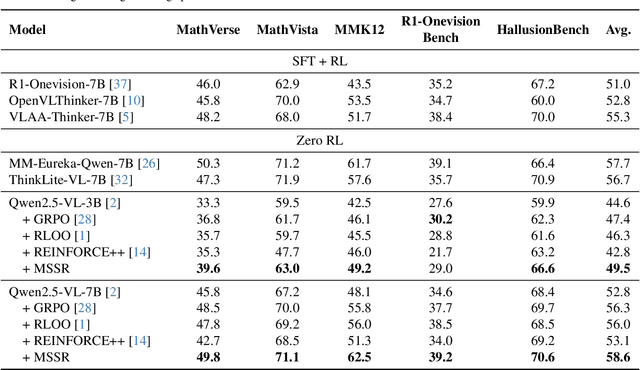
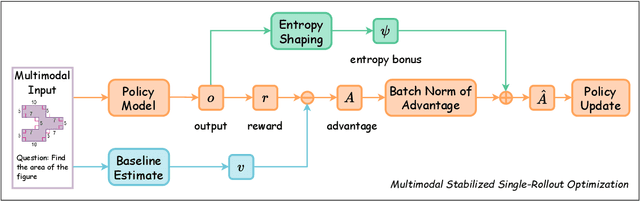

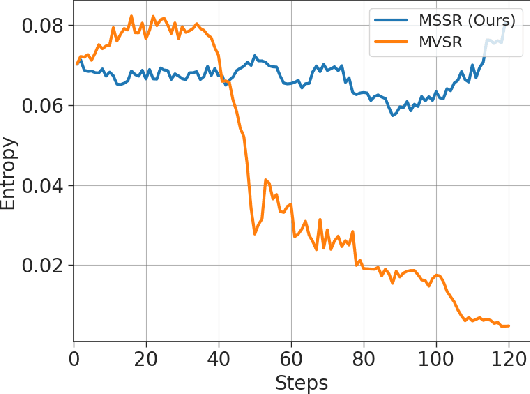
Reinforcement Learning with Verifiable Rewards (RLVR) has become a key paradigm to improve the reasoning capabilities of Multimodal Large Language Models (MLLMs). However, prevalent group-based algorithms such as GRPO require multi-rollout sampling for each prompt. While more efficient single-rollout variants have recently been explored in text-only settings, we find that they suffer from severe instability in multimodal contexts, often leading to training collapse. To address this training efficiency-stability trade-off, we introduce $\textbf{MSSR}$ (Multimodal Stabilized Single-Rollout), a group-free RLVR framework that achieves both stable optimization and effective multimodal reasoning performance. MSSR achieves this via an entropy-based advantage-shaping mechanism that adaptively regularizes advantage magnitudes, preventing collapse and maintaining training stability. While such mechanisms have been used in group-based RLVR, we show that in the multimodal single-rollout setting they are not merely beneficial but essential for stability. In in-distribution evaluations, MSSR demonstrates superior training compute efficiency, achieving similar validation accuracy to the group-based baseline with half the training steps. When trained for the same number of steps, MSSR's performance surpasses the group-based baseline and shows consistent generalization improvements across five diverse reasoning-intensive benchmarks. Together, these results demonstrate that MSSR enables stable, compute-efficient, and effective RLVR for complex multimodal reasoning tasks.
Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning
Dec 17, 2025



Reinforcement learning has become essential for strengthening the reasoning abilities of large language models, yet current exploration mechanisms remain fundamentally misaligned with how these models actually learn. Entropy bonuses and external semantic comparators encourage surface level variation but offer no guarantee that sampled trajectories differ in the update directions that shape optimization. We propose G2RL, a gradient guided reinforcement learning framework in which exploration is driven not by external heuristics but by the model own first order update geometry. For each response, G2RL constructs a sequence level feature from the model final layer sensitivity, obtainable at negligible cost from a standard forward pass, and measures how each trajectory would reshape the policy by comparing these features within a sampled group. Trajectories that introduce novel gradient directions receive a bounded multiplicative reward scaler, while redundant or off manifold updates are deemphasized, yielding a self referential exploration signal that is naturally aligned with PPO style stability and KL control. Across math and general reasoning benchmarks (MATH500, AMC, AIME24, AIME25, GPQA, MMLUpro) on Qwen3 base 1.7B and 4B models, G2RL consistently improves pass@1, maj@16, and pass@k over entropy based GRPO and external embedding methods. Analyzing the induced geometry, we find that G2RL expands exploration into substantially more orthogonal and often opposing gradient directions while maintaining semantic coherence, revealing that a policy own update space provides a far more faithful and effective basis for guiding exploration in large language model reinforcement learning.